Lock Contention
Overview
Recently, I revisited Resolving a year-long ClickHouse lock contention post and spoke about it at C++ Russia 2025 conference.
I wanted to provide more information about the development process and some technical details that were not covered in the original post.
Motivation
In 2022 in Tinybird, there was a huge CPU underutilization in one of our clusters during the high load period.
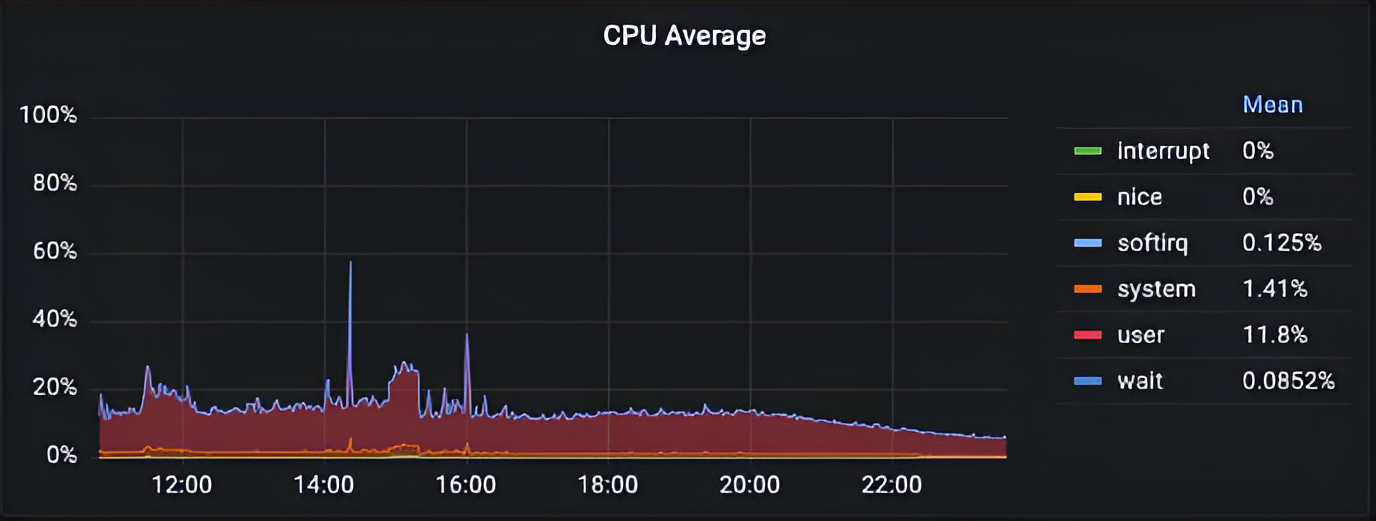
It was unclear what was the issue. There were no IO/Network/Memory bottlenecks. In ClickHouse all async metrics and query profile events were normal. The only unusual thing was that with increased queries throughput, ClickHouse could not handle the load, and CPU usage was very low.
The problem continued for a year and during similar incidents, we could not find any clues.
One year later during a similar incident, we spotted that ContextLockWait async metric periodically increased. Async metrics are calculated periodically with some interval and include for example memory usage, and some global metrics. Client can read them using system.asynchronous_metrics table. And one of such metrics is ContextLockWait, it tells you how many threads are waiting for a Context lock.

It is normal that during high load such metric can increase because of increased contention on Context lock. But it was very unusual because the normal value of this metric is around 0, so I started to investigate the issue from the ClickHouse internals side.
During the incident, I periodically dumped all threads stack traces to understand how many threads were blocked on lock inside Context. It is possible to dump all threads stack traces in ClickHouse using system.stack_trace table and the following query:
WITH arrayMap(x -> demangle(addressToSymbol(x)), trace) AS all SELECT thread_name, thread_id, query_id, arrayStringConcat(all, '\n') AS res FROM system.stack_trace LIMIT 1 FORMAT Vertical; Row 1: ────── thread_name: clickhouse-serv thread_id: 125441 query_id: res: pthread_cond_wait std::__1::condition_variable::wait(std::__1::unique_lock<std::__1::mutex>&) BaseDaemon::waitForTerminationRequest() DB::Server::main(/*arguments*/) Poco::Util::Application::run() DB::Server::run() Poco::Util::ServerApplication::run(int, char**) mainEntryClickHouseServer(int, char**) main __libc_start_main _start
Every 10-15 seconds I dumped all threads stack traces to later check if there were any patterns where threads were spending time. After the incident, I was able to see that most of the threads were blocked on Context class methods that needed to take a Context lock, for example Context::getSettings().
After that I was almost sure that the problem was in Context lock contention and started to investigate this particular lock.
Adding ContextLockWaitMicroseconds
In ClickHouse there are per query profile events that are defined like this:
M(GlobalThreadPoolJobs, "Counts the number of jobs that have been pushed to the global thread pool.", ValueType::Number) \ M(GlobalThreadPoolLockWaitMicroseconds, "Total time threads have spent waiting for locks in the global thread pool.", ValueType::Microseconds) \ M(GlobalThreadPoolJobWaitTimeMicroseconds, "Measures the elapsed time from when a job is scheduled in the thread pool to when it is picked up for execution by a worker thread. This metric helps identify delays in job processing, indicating the responsiveness of the thread pool to new tasks.", ValueType::Microseconds) \ M(LocalThreadPoolLockWaitMicroseconds, "Total time threads have spent waiting for locks in the local thread pools.", ValueType::Microseconds) \
As you can see they can have different types like ValueType::Number or ValueType::Microseconds. We already have a lot of metrics for locks for which we can have heavy contention. For example,
you can see that there is GlobalThreadPoolLockWaitMicroseconds event that allows you to see how much time threads spend waiting for locks in the global thread pool. Unfortunately,
for Context lock we did not have a similar metric, we only had ContextLock event that tells you how many times the Context lock was acquired or tried to acquire. It is not enough to
understand if there is a problem with Context lock contention, because it is expected that query can take this lock many times during query execution to read query settings, query current database, etc. We need a metric that tells us how much time threads in the query spend waiting for a Context lock, similar to the GlobalThreadPoolLockWaitMicroseconds event.
The first step was to add the ContextLockWaitMicroseconds event to profile events in https://github.com/ClickHouse/ClickHouse/pull/55029:
M(ContextLock,
"Number of times the lock of Context was acquired or tried to acquire. This is global lock.",
ValueType::Number) \
M(ContextLockWaitMicroseconds,
"Context lock wait time in microseconds",
ValueType::Microseconds) \
During the development of the pull request, I already discovered that the problem was in the Context lock because I was able to reproduce performance issue locally using the ContextLockWaitMicroseconds metric to track the amount of time threads in the query spend waiting for the Context lock.
I took an example query that takes 5 milliseconds to execute:
SELECT UserID, count(*) FROM (SELECT * FROM hits_clickbench LIMIT 10) GROUP BY UserID 0 rows in set. Elapsed: 0.005 sec.
And tried to run 200 such queries concurrently for a couple of minutes:
clickhouse-benchmark --query="SELECT UserID, count(*) FROM (SELECT * FROM hits_clickbench LIMIT 10) GROUP BY UserID" --concurrency=200
And checked the results:
SELECT quantileExact(0.5)(lock_wait_milliseconds), max(lock_wait_milliseconds) FROM
(
SELECT (ProfileEvents['ContextLockWaitMicroseconds'] / 1000.0) AS lock_wait_milliseconds
FROM system.query_log WHERE lock_wait_milliseconds > 0
)
┌─quantileExact(0.5)(lock_wait_milliseconds)─┬─max(lock_wait_milliseconds)──┐
│ 17.452 │ 382.326 │
└────────────────────────────────────────────┴──────────────────────────────┘
As you can see, some queries wait for the Context lock for 382 milliseconds, and the median wait time is 17 milliseconds, which is unacceptable.
Context Lock Redesign
There are actually two types of Context in ClickHouse:
-
ContextSharedPartis responsible for storing and providing access to global shared objects that are shared between all sessions and queries, for example: Thread pools, Server paths, Global trackers, Clusters information. -
Contextis responsible for storing and providing access to query or session-specific objects, for example: query settings, query caches, query current database.
Architecture before redesign looked like this:

The problem was that a single mutex was used for most of the synchronization between Context and ContextSharedPart, even when we worked with objects local to Context. For example, when a thread wants to read local query settings from Context, it needs to lock the ContextSharedPart mutex, which leads to huge contention if there is a high number of low latency queries.
During query execution, ClickHouse can create a lot of Contexts because each subquery in ClickHouse can have unique settings. For example:
SELECT id, value
FROM (
SELECT id, value
FROM test_table
SETTINGS max_threads = 16
)
WHERE id > 10
SETTINGS max_threads = 32
In this example, we want to execute the inner subquery with max_threads = 16 and the outer subquery with max_threads = 32. A large number of low latency, concurrent queries with many subqueries will create a lot of Contexts per query, and the problem will become even bigger.
It is actually common to have global Context or ApplicationContext classes in projects and put everything in them. When synchronization is required, it is usually implemented initially with a single mutex. But later, if lock contention becomes an issue, it needs to be redesigned to use a more sophisticated approach.
The idea was to replace a single global mutex with two read-write mutexes readers–writer lock. One global read-write mutex for ContextSharedPart and one local read-write mutex for each Context.
Read-write mutexes are used because we usually do a lot of concurrent reads (for example, read settings or some path) and rarely concurrent writes. For example, for ContextSharedPart object, we could rewrite some fields during configuration hot reload, but it is very rare. For Context object during query execution query current database, query settings are almost never changed after the query is parsed and analyzed.
In many places, I completely got rid of synchronization where it was used for initialization of some objects and used call_once for objects that are initialized only once.
Context lock redesign was implemented in the scope of the pull request: https://github.com/ClickHouse/ClickHouse/pull/55121.
Here is how the architecture looks after redesign:

Thread Safety Analysis
Context lock redesign was conceptually very simple, but it was very hard to implement it correctly without introducing synchronization issues. ContextSharedPart and Context both contain a lot of fields and methods with complex synchronization logic and it was very hard to properly split synchronization between them manually. It was unclear how to be sure that all locks were used properly and that there were no synchronization issues after refactoring.
The solution was to use Clang Thread Safety Analysis and add necessary annotations to mutexes, fields, and methods of Context and ContextSharedPart. Now I want to explain in detail how this was done and what problems I had.
To use Clang thread safety analysis, compile your code with the -Wthread-safety flag. In production, you need to use -Werror or mark this particular thread-safety warning as an error.
clang -c -Wthread-safety example.cpp
In Clang thread safety analysis documentation, there is an example of how to use thread safety annotations:
class BankAccount {
private:
Mutex mu;
int balance GUARDED_BY(mu);
void depositImpl(int amount) /* TO FIX: REQUIRES(mu) */ {
balance += amount; // WARNING! Cannot write balance without locking mu.
}
void withdrawImpl(int amount) REQUIRES(mu) {
balance -= amount; // OK. Caller must have locked mu.
}
public:
void withdraw(int amount) {
mu.Lock();
withdrawImpl(amount); // OK. We've locked mu.
/* TO FIX: mu.unlock() or use std::lock_guard */
} // WARNING! Failed to unlock mu.
void transferFrom(BankAccount& b, int amount) {
mu.Lock();
/* TO FIX: lock() and unlock() b.mu potentially use std::lock_guard*/
b.withdrawImpl(amount); // WARNING! Calling withdrawImpl() requires locking b.mu.
depositImpl(amount); // OK. depositImpl() has no requirements.
mu.Unlock();
}
};
I added TO FIX comments to fix warnings in places where you will see warnings after running thread safety analysis. Here are the most important concepts from Clang
thread safety analysis documentation:
Thread safety analysis provides a way of protecting resources with capabilities. A resource is either a data member, or a function/method that provides access to some underlying resource. The analysis ensures that the calling thread cannot access the resource (i.e. call the function, or read/write the data) unless it has the capability to do so.
A thread may hold a capability either exclusively or shared. An exclusive capability can be held by only one thread at a time, while a shared capability can be held by many threads at the same time. This mechanism enforces a multiple-reader, single-writer pattern. Write operations to protected data require exclusive access, while read operations require only shared access.
Capabilities are associated with named C++ objects which declare specific methods to acquire and release the capability. The name of the object serves to identify the capability. The most common example is a mutex. For example, if
muis a mutex, then callingmu.Lock()causes the calling thread to acquire the capability to access data that is protected bymu. Similarly, callingmu.Unlock()releases that capability.
Clang thread safety annotations can be split into three different categories. Here are the most commonly used annotations:
- For the implementation of capability classes and functions:
CAPABILITY(...),SCOPED_CAPABILITY,ACQUIRE(…),ACQUIRE_SHARED(…),RELEASE(…),RELEASE_SHARED(…),RELEASE_GENERIC(…) - For protecting fields and methods:
GUARDED_BY(...),PT_GUARDED_BY(...),REQUIRES(…),REQUIRES_SHARED(…) - Utility:
NO_THREAD_SAFETY_ANALYSIS
Those annotations are very flexible and allow you to combine them in different ways. For example, you can use REQUIRES annotation that takes multiple mutexes:
Mutex mutex_1, mutex_2;
int a GUARDED_BY(mutex_1);
int b GUARDED_BY(mutex_2);
void test() REQUIRES(mutex_1, mutex_2) {
a = 0;
b = 0;
}
In the LLVM standard library, all mutex implementations are annotated with thread safety annotations. Example std::mutex:
class _LIBCPP_TYPE_VIS _LIBCPP_THREAD_SAFETY_ANNOTATION(capability("mutex")) mutex
{
__libcpp_mutex_t __m_ = _LIBCPP_MUTEX_INITIALIZER;
public:
_LIBCPP_INLINE_VISIBILITY
_LIBCPP_CONSTEXPR mutex() = default;
mutex(const mutex&) = delete;
mutex& operator=(const mutex&) = delete;
#if defined(_LIBCPP_HAS_TRIVIAL_MUTEX_DESTRUCTION)
~mutex() = default;
#else
~mutex() _NOEXCEPT;
#endif
void lock() _LIBCPP_THREAD_SAFETY_ANNOTATION(acquire_capability());
bool try_lock() _NOEXCEPT _LIBCPP_THREAD_SAFETY_ANNOTATION(try_acquire_capability(true));
void unlock() _NOEXCEPT _LIBCPP_THREAD_SAFETY_ANNOTATION(release_capability());
typedef __libcpp_mutex_t* native_handle_type;
_LIBCPP_INLINE_VISIBILITY native_handle_type native_handle() {return &__m_;}
};
Clang thread safety analysis is a great tool for catching synchronization errors in code. However, it can have some problems for production usage out of the box.
ClickHouse has its own implementation of some synchronization primitives, such as the implementation of std::shared_mutex, because the standard library implementation is slow. We also want to have mutexes with additional logic during lock/unlock, such as updating metrics or profile events. In both cases, we do not want to have a lot of duplicated thread safety annotations in all of our mutexes. We want to hide them and have a generic solution.
To solve this problems, I designed SharedMutexHelper template class using CRTP pattern that implements SharedMutex standard library requirements https://en.cppreference.com/w/cpp/named_req/SharedMutex and adds thread safety annotations.
template <typename Derived, typename MutexType = SharedMutex>
class TSA_CAPABILITY("SharedMutexHelper") SharedMutexHelper
{
auto & getDerived() { return static_cast<Derived &>(*this); }
public:
// Exclusive ownership
void lock() TSA_ACQUIRE() { getDerived().lockImpl(); }
bool try_lock() TSA_TRY_ACQUIRE(true) { getDerived().tryLockImpl(); }
void unlock() TSA_RELEASE() { getDerived().unlockImpl(); }
// Shared ownership
void lock_shared() TSA_ACQUIRE_SHARED() { getDerived().lockSharedImpl(); }
bool try_lock_shared() TSA_TRY_ACQUIRE_SHARED(true) { getDerived().tryLockSharedImpl(); }
void unlock_shared() TSA_RELEASE_SHARED() { getDerived().unlockSharedImpl(); }
protected:
/// Default implementations for all *Impl methods.
void lockImpl() TSA_NO_THREAD_SAFETY_ANALYSIS { mutex.lock(); }
...
void unlockSharedImpl() TSA_NO_THREAD_SAFETY_ANALYSIS { mutex.unlock_shared(); }
MutexType mutex;
};
SharedMutexHelper implements all necessary methods for SharedMutex requirements and, by default, delegates all methods to MutexType implementation. The derived class must subclass SharedMutexHelper and override only the necessary lockImpl, tryLockImpl, unlockImpl, lockSharedImpl, tryLockSharedImpl, and unlockSharedImpl methods.
Here is a concrete implementation of ContextSharedMutex:
class ContextSharedMutex : public SharedMutexHelper<ContextSharedMutex>
{
private:
using Base = SharedMutexHelper<ContextSharedMutex, SharedMutex>;
friend class SharedMutexHelper<ContextSharedMutex, SharedMutex>;
void lockImpl()
{
ProfileEvents::increment(ProfileEvents::ContextLock);
CurrentMetrics::Increment increment{CurrentMetrics::ContextLockWait};
Stopwatch watch;
Base::lockImpl();
ProfileEvents::increment(ProfileEvents::ContextLockWaitMicroseconds,
watch.elapsedMicroseconds());
}
void lockSharedImpl()
{
ProfileEvents::increment(ProfileEvents::ContextLock);
CurrentMetrics::Increment increment{CurrentMetrics::ContextLockWait};
Stopwatch watch;
Base::lockSharedImpl();
ProfileEvents::increment(ProfileEvents::ContextLockWaitMicroseconds,
watch.elapsedMicroseconds());
}
};
As you can see, ContextSharedMutex overrides only lockImpl and lockSharedImpl methods and, in these methods, updates metrics.
Another problem was that in the LLVM standard library, std::shared_lock does not support thread safety analysis. This is probably because this class is movable, and thread safety annotations do not have support for movable locks. For example, std::unique_lock also does not support thread safety analysis.
To solve this issue, I implemented SharedLockGuard analog of std::lock_guard, but for shared mutexes:
template <typename Mutex>
class TSA_SCOPED_LOCKABLE SharedLockGuard
{
public:
explicit SharedLockGuard(Mutex & mutex_) TSA_ACQUIRE_SHARED(mutex_)
: mutex(mutex_) { mutex_.lock_shared(); }
~SharedLockGuard() TSA_RELEASE() { mutex.unlock_shared(); }
private:
Mutex & mutex;
};
Let’s see an example of thread safety analysis usage in ContextSharedPart. We declare which fields are guarded by ContextSharedMutex mutex.
struct ContextSharedPart : boost::noncopyable
{
/// For access of most of shared objects.
mutable ContextSharedMutex mutex;
/// Path to the data directory, with a slash at the end.
String path TSA_GUARDED_BY(mutex);
/// Path to the directory with some control flags for server maintenance.
String flags_path TSA_GUARDED_BY(mutex);
/// Path to the directory with user provided files, usable by 'file' table function.
String dictionaries_lib_path TSA_GUARDED_BY(mutex);
/// Path to the directory with user provided scripts.
String user_scripts_path TSA_GUARDED_BY(mutex);
/// Path to the directory with filesystem caches.
String filesystem_caches_path TSA_GUARDED_BY(mutex);
/// Path to the directory with user provided filesystem caches.
String filesystem_cache_user_path TSA_GUARDED_BY(mutex);
/// Global configuration settings.
ConfigurationPtr config TSA_GUARDED_BY(mutex);
};
Then, in ContextSharedPart methods that need to access guarded fields, we use SharedLockGuard for shared access or std::lock_guard for exclusive access:
String Context::getPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->path;
}
String Context::getFlagsPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->flags_path;
}
String Context::getUserFilesPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->user_files_path;
}
String Context::getDictionariesLibPath() const
{
SharedLockGuard lock(shared->mutex);
return shared->dictionaries_lib_path;
}
void Context::setPath(const String & path)
{
std::lock_guard lock(shared->mutex);
shared->path = path;
if (shared->tmp_path.empty() && !shared->root_temp_data_on_disk)
shared->tmp_path = shared->path + "tmp/";
if (shared->flags_path.empty())
shared->flags_path = shared->path + "flags/";
if (shared->user_files_path.empty())
shared->user_files_path = shared->path + "user_files/";
if (shared->dictionaries_lib_path.empty())
shared->dictionaries_lib_path = shared->path + "dictionaries_lib/";
if (shared->user_scripts_path.empty())
shared->user_scripts_path = shared->path + "user_scripts/";
}
I implemented thread safety analysis refactoring in this pull request https://github.com/ClickHouse/ClickHouse/pull/55278.
Performance improvements
In Tinybird, we had a synthetic benchmark that contained a lot of low latency queries. We ran this benchmark with the old and new ClickHouse version (after Context lock redesign):
clickhouse benchmark -r --ignore-error \ --concurrency=500 \ --timelimit 600 \ --connect_timeout=20 < queries.txt
And had the following results:
-
Before ~200 QPS. After ~600 QPS (~3x better).
-
Before CPU utilization of only ~20%. After ~60% (~3x better).
-
Before median query time 1s. After ~0.6s (~2x better).
-
Before slowest queries took ~75s. After ~6s (~12x better).
As you can see in such benchmark, we were not able to utilize ClickHouse to 100% CPU usage because of low concurrency. We were able to fully utilize ClickHouse instance with --concurrency=1000 and had
around ~1000 QPS and ~95-96% CPU utilization.
With more complex production queries, ClickHouse will most likely hit another bottleneck. However, we definitely removed Context lock contention as a potential bottleneck.
Conclusion
Lock contention is a very common source of performance issues in modern high concurrency systems. You can think of it the same way as a CPU/Memory/IO/Network bound, like the LockContention bound.
To detect such issues you can try to use off-cpu analysis and introduce additional application level metrics that will tell you how much time threads spend in different locks.
It is also a good idea to use all available tooling as much as possible, including runtime tools like address/memory/thread/undefined-behavior sanitizers and compile-time tools like Clang thread safety analysis.