ExpressionTransform
SELECT a + b + c FROM test_table;
Expressions are represented in DAG that has input, function, constant types of node. Example:

Maksim, developer of ClickHouse.
1. ClickHouse query execution.
2. JIT compilation.
3. ClickHouse compilation of expressions.
4. ClickHouse compilation of operator GROUP BY.
5. ClickHouse compilation of ORDER BY comparator.
Column-oriented storage — data is physically stored by columns. Only necessary columns are read from disk during query.
Vectorized query execution — data is processed in blocks. Block contains multiple columns with max_block_size rows (65536 by default).
Each column is stored as a vector of primitive data types or their combination:
1. Better utilization for CPU caches and pipeline.
2. Data is processed using SIMD instructions.
Numeric columns — PODArray. Almost the same as std::vector.
1. Use our Allocator with support of realloc.
2. No additional memset during resize.
3. Padding with 15 bytes at the end.
Nullable columns contain data column and UInt8 column bitmask is element null.
Array columns contain data column and UInt64 column with offsets.
Const column contain 1 constant value.
Takes arguments as columns and returns function result as column.
class IFunction
{
virtual ~IFunction() = default;
virtual ColumnPtr executeImpl(
const ColumnsWithTypeAndName & arguments,
const DataTypePtr & result_type,
size_t input_rows_count) const = 0;
...
}
Specializations using templates for different types. Example plus, multiply for different types combinations.
Specializations for constant columns. Example plus, multiply with constant column.
Function plus has:
UInt8 UInt16 UInt32 UInt64 UInt8 UInt16 UInt32 UInt64
Int8 Int16 Int32 Int64 ✕ Int8 Int16 Int32 Int64
Float32 Float64 Float32 Float64
specialization.
In addition specialization if one of the columns is a constant column
20 x 20 = 400 specializations for single plus function.
Advantages:
1. Code isolation.
2. High efficiency (Necessary specializations can be generated).
3. Compiler can generate SIMD instructions.
Disadvantages:
1. Heavy template usage (Templates can be complex).
2. Binary code bloat.
3. No way to fuse multiple expressions into one. Example: x * y + 5.
1. Parse query into AST.
2. Make AST optimizations (Most of them need to be moved into logical, physical query plans or expression DAG optimizations).
3. Build logical query plan + make logical query plan optimizations.
4. Build physical query plan + make physical query plan optimizations.
5. Execution.
EXPLAIN AST value * 2 + 1 FROM test_table
WHERE value > 10 ORDER BY value;
┌─explain─────────────────────────────────────┐
│ SelectWithUnionQuery (children 1) │
│ ExpressionList (children 1) │
│ SelectQuery (children 4) │
│ ExpressionList (children 1) │
│ Function plus (children 1) │
│ ExpressionList (children 2) │
│ Function multiply (children 1) │
│ ExpressionList (children 2) │
│ Identifier value │
│ Literal UInt64_2 │
│ Literal UInt64_1 │
│ TablesInSelectQuery (children 1) │
│ TablesInSelectQueryElement (children 1) │
│ TableExpression (children 1) │
│ TableIdentifier test_table │
│ Function greater (children 1) │
│ ExpressionList (children 2) │
│ Identifier value │
│ Literal UInt64_10 │
│ ExpressionList (children 1) │
│ OrderByElement (children 1) │
│ Identifier value │
└─────────────────────────────────────────────┘
EXPLAIN SELECT value * 2 + 1 FROM test_table
WHERE value > 10 ORDER BY value;
┌─explain──────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY [lifted up part])) │
│ Sorting (Sorting for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Filter (WHERE) │
│ SettingQuotaAndLimits │
│ ReadFromMergeTree (default.test_table) │
└──────────────────────────────────────────────────────────────────┘
EXPLAIN PIPELINE SELECT value * 2 + 1 FROM test_table
WHERE value > 10 ORDER BY value;
┌─explain────────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Sorting) │
│ MergingSortedTransform 16 → 1 │
│ MergeSortingTransform × 16 │
│ LimitsCheckingTransform × 16 │
│ PartialSortingTransform × 16 │
│ (Expression) │
│ ExpressionTransform × 16 │
│ (Filter) │
│ FilterTransform × 16 │
│ (SettingQuotaAndLimits) │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 16 0 → 1 │
└────────────────────────────────────────────┘
JIT - Just in time compilation
Generate machine code and execute in runtime.
Examples: JVM Hotspot, V8.
Use LLVM for JIT compilation.
Use our own wrapper around LLVM dynamic linker and compiler.
2018 - First implementation for JIT compilation of expressions. Developer Denis Skorobogatov.
2019 - Improvements in initial implementation. Enable by default in production. Developers Alexey Milovidov, Alexander Sapin.
2019 - Disable JIT by default. Available as an experimental feature.
2021 - Fix issues with JIT compilation of expressions. Enable JIT compilation by default. Developer Maksim Kita.
2021 - Implement JIT compilation for GROUP BY operator.
2022 - Implement JIT compilation for ORDER BY comparator.
EXPLAIN PIPELINE SELECT value * 2 + 1 FROM test_table
WHERE value > 10 ORDER BY value;
┌─explain────────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Sorting) │
│ MergingSortedTransform 16 → 1 │
│ MergeSortingTransform × 16 │
│ LimitsCheckingTransform × 16 │
│ PartialSortingTransform × 16 │
│ (Expression) │
│ ExpressionTransform × 16 │
│ (Filter) │
│ FilterTransform × 16 │
│ (SettingQuotaAndLimits) │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 16 0 → 1 │
└────────────────────────────────────────────┘
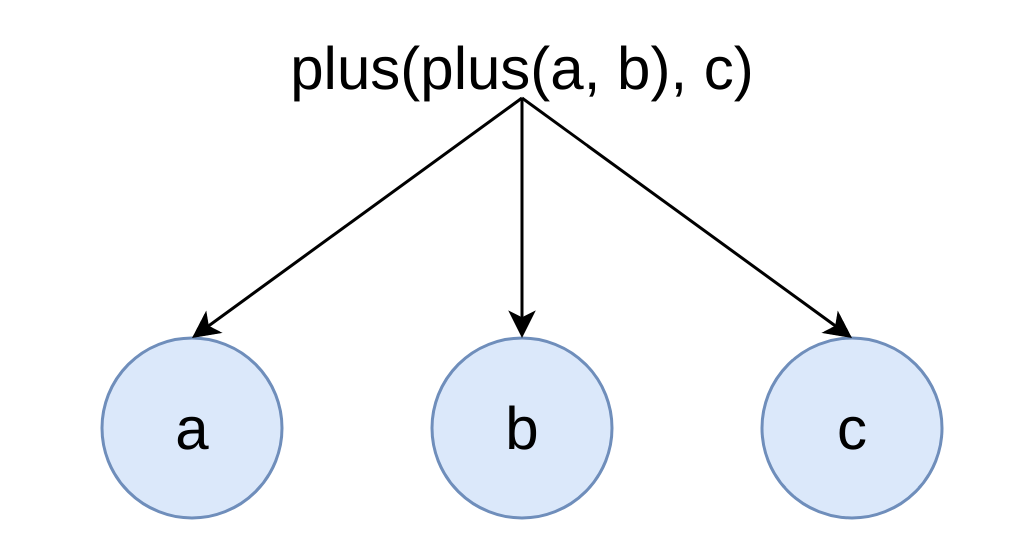
SELECT a + b + c FROM test_table;
Expressions are represented in DAG that has input, function, constant types of node. Example:
1. During DAG interpretation, data is moving between functions. Operations are not fused.
Example plus(plus(a, b), c)) first plus on columns a and b is performed and the result stored in a temporary column.. Then plus with temporary column and column c is performed.
2. Code bloat for different function specializations using templates, increases binary size.
3. For AVX256, AVX512 instructions need to use runtime instructions specialization using CPUID. Necessary for distributing portable binary.
1. For each node in ActionsDAG get compilable_children_size
2. Sort nodes in descending order of compilable_children_size, to first compile nodes with most children.
3. Check if node can be compiled using heuristics. Currently we require node to contain at least 1 compilable children.
4. Compile node functions together into a function that takes raw columns data pointers and returns expression result.
4. Replace node in DAG with special LLVMFunction node. LLVMFunction execute method converts columns into raw data and calls compiled function
SELECT a + b + c FROM test_table;
SET compile_expressions = 1;
SELECT a + b + c FROM test_table;
1. Improve L1, L2 cache usages.
2. Less code to execute. It is placed on 1 page. Better usage of CPU branch predictor.
3. Eliminate indirections.
4. Multiple operations are fused in one function. More optimizations can be performed by the compiler.
5. Using target CPU instructions (AVX256, AVX512) if necessary.
Any function potentially can be compiled, but generating IR is inconvenient. Currently supported:
1. Binary operators. Example: plus, minus, multiply, xor.
2. Unary operators. Example: abs.
3. Logical functions. Example: and, or, not.
4. Branch functions. Example: if, multiIf.
5. Bit shift functions. Example: bitShiftLeft.
SELECT a + b * c + 5 FROM test_jit_merge_tree;
loop: ; preds = %loop, %entry
%19 = phi i64 [ 0, %entry ], [ %34, %loop ] /// Get counter phi node. If started from entry it is 0.
%20 = phi i64* [ %5, %entry ], [ %30, %loop ] /// Argument column phi node
%21 = phi i64* [ %9, %entry ], [ %31, %loop ] /// Argument column phi node
%22 = phi i64* [ %13, %entry ], [ %32, %loop ] /// Argument column phi node
%23 = phi i64* [ %17, %entry ], [ %33, %loop ] /// Result column phi node
%24 = load i64, i64* %20, align 8 /// Load argument current row
%25 = load i64, i64* %21, align 8 /// Load argument current row
%26 = load i64, i64* %22, align 8 /// Load argument current row
%27 = mul i64 %25, %26 /// Multiply b * c
%28 = add i64 %24, %27 /// Add a + result of multiply b * c
%29 = add i64 %28, 5 /// Add with constant 5
store i64 %29, i64* %23, align 8 /// Store value in result column
%30 = getelementptr inbounds i64, i64* %20, i64 1 /// Adjust pointer to next element
%31 = getelementptr inbounds i64, i64* %21, i64 1 /// Adjust pointer to next element
%32 = getelementptr inbounds i64, i64* %22, i64 1 /// Adjust pointer to next element
%33 = getelementptr inbounds i64, i64* %23, i64 1 /// Adjust pointer to next element
%34 = add i64 %19, 1 /// Increase counter
%35 = icmp eq i64 %34, %0br i1 %35, label %end, label %loop /// Check loop predicate
void aPlusBMulitplyCPlusConstant(
int64_t * a,
int64_t * b,
int64_t * c,
int64_t constant,
int64_t * result,
size_t size)
{
for (size_t i = 0; i < size; ++i)
{
*result = (*a) + (*b) * (*c) + constant;
++a;
++b;
++c;
++result;
}
}
.LBB0_8: # %vector.body
vmovdqu (%r11,%rax,8), %ymm1
vmovdqu (%r9,%rax,8), %ymm3
vmovdqu 32(%r11,%rax,8), %ymm2
vmovdqu 32(%r9,%rax,8), %ymm4
vpsrlq $32, %ymm3, %ymm5
vpsrlq $32, %ymm1, %ymm6
vpmuludq %ymm1, %ymm5, %ymm5
vpmuludq %ymm6, %ymm3, %ymm6
vpmuludq %ymm1, %ymm3, %ymm1
vpsrlq $32, %ymm4, %ymm3
vpmuludq %ymm2, %ymm3, %ymm3
vpaddq %ymm5, %ymm6, %ymm5
vpsllq $32, %ymm5, %ymm5
vpaddq %ymm5, %ymm1, %ymm1
vpsrlq $32, %ymm2, %ymm5
vpmuludq %ymm2, %ymm4, %ymm2
vpaddq (%r14,%rax,8), %ymm1, %ymm1
vpmuludq %ymm5, %ymm4, %ymm5
vpaddq %ymm3, %ymm5, %ymm3
vpsllq $32, %ymm3, %ymm3
vpaddq %ymm3, %ymm2, %ymm2
vpaddq 32(%r14,%rax,8), %ymm2, %ymm2
vpaddq %ymm0, %ymm1, %ymm1 /// in ymm0 there is constant 5. vpbroadcastq (%rbp), %ymm0
vmovdqu %ymm1, (%r10,%rax,8)
vpaddq %ymm0, %ymm2, %ymm2
vmovdqu %ymm2, 32(%r10,%rax,8)
addq $8, %rax
cmpq %rax, %r8
JIT standard expression compilation time is around 15 ms. Grows linearly with code size.
Typical compiled expressions use 1 page for the code section and 1 page for the data section. 4096 * 2 = 8192 bytes on most configurations.
Introspection works inside ClickHouse using `CompileExpressionsMicroseconds`, `CompileExpressionsBytes` metrics.
SELECT
ProfileEvents['CompileExpressionsMicroseconds'] AS compiled_time,
ProfileEvents['CompileExpressionsBytes'] AS compiled_bytes
FROM system.query_log
WHERE compiled_time > 0;
┌─compiled_time─┬─compiled_bytes─┐
│ 16258 │ 8192 │
│ 26792 │ 8192 │
│ 15280 │ 8192 │
│ 11594 │ 8192 │
│ 14989 │ 8192 │
└───────────────┴────────────────┘
SELECT count() FROM hits
WHERE
((EventDate >= '2018-08-01')
AND (EventDate <= '2018-08-03')
AND (CounterID >= 34))
OR ((EventDate >= '2018-08-04')
AND (EventDate <= '2018-08-05')
AND (CounterID <= 101500))
— 649 533 033 rows per second.
SET compile_expressions = 1;
SELECT count() FROM hits
WHERE
((EventDate >= '2018-08-01')
AND (EventDate <= '2018-08-03')
AND (CounterID >= 34))
OR ((EventDate >= '2018-08-04')
AND (EventDate <= '2018-08-05')
AND (CounterID <= 101500))
— 865 491 052 rows per second.
— +33% performance improvement!
SELECT
number * 2 +
number * 3 +
number * 4 +
number * 5
FROM system.numbers
FORMAT Null
— 0 rows in set. Elapsed: 0.903 sec. Processed 329.23 million rows, 2.63 GB (364.78 million rows/s., 2.92 GB/s.
SET compile_expressions = 1;
SELECT
number * 2 +
number * 3 +
number * 4 +
number * 5
FROM system.numbers
FORMAT Null
— 0 rows in set. Elapsed: 1.602 sec. Processed 1.89 billion rows, 15.15 GB (1.18 billion rows/s., 9.46 GB/s.)
—
+323% performance improvement!
SET compile_expressions = 1;
WITH number AS x, if(x = 1, 1, if(x = 2, 2,
if(x = 3, 3, if(x = 4, 4, if(x = 5, 5,
if(x = 6, 6, if(x = 7, 7, if(x = 8, 8,
if(x = 9, 9, if(x = 10, 10,
if(x = 11, 11, 12))))))))))) AS res
SELECT sum(res)
FROM numbers(10000000)
— 0 rows in set. Elapsed: 0.150 sec. Processed 10.02 million rows, 80.18 MB (66.95 million rows/s., 535.56 MB/s.).
SET compile_expressions = 1;
WITH number AS x, if(x = 1, 1, if(x = 2, 2,
if(x = 3, 3, if(x = 4, 4, if(x = 5, 5,
if(x = 6, 6, if(x = 7, 7, if(x = 8, 8,
if(x = 9, 9, if(x = 10, 10,
if(x = 11, 11, 12))))))))))) AS res
SELECT sum(res)
FROM numbers(10000000)
— 0 rows in set. Elapsed: 0.061 sec. Processed 10.02 million rows, 80.18 MB (163.20 million rows/s., 1.31 GB/s.)
—
+244% performance improvement!

EXPLAIN PIPELINE SELECT sum(UserID)
FROM default.hits_100m_single GROUP BY WatchID;
┌─explain────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Aggregating) │
│ Resize 16 → 1 │
│ AggregatingTransform × 15 │
│ StrictResize 16 → 16 │
│ (Expression) │
│ ExpressionTransform × 16 │
│ (SettingQuotaAndLimits) │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 16 0 → 1 │
└────────────────────────────────────────┘

class IAggregateFunction
{
...
virtual ~IAggregateFunction() = default;
/// AggregateDataPtr pointer to aggregate data for unique key during GROUP BY
/// Create empty data for aggregation with `placement new` at the specified location.
virtual void create(AggregateDataPtr place) const = 0;
/** Adds a value into aggregation data on which place points to.
* columns points to columns containing arguments of aggregation function.
* row_num is number of row which should be added.
*/
virtual void add(
AggregateDataPtr place,
const IColumn ** columns,
size_t row_num,
Arena * arena) const = 0;
/// Merges state (on which place points to) with other state of current aggregation function.
virtual void merge(AggregateDataPtr place, ConstAggregateDataPtr rhs, Arena * arena) const = 0;
/// Inserts results into a column. This method might modify the state (e.g.
/// sort an array), so must be called once, from single thread.
virtual void insertResultInto(AggregateDataPtr place, IColumn & to, Arena * arena) const = 0;
...
}
SELECT
sum(UserID),
sum(ClientIP),
sum(CounterClass),
sum(CounterID),
sum(WatchID)
FROM default.hits_100m_obfuscated
GROUP BY WatchID
1. For each unique key, create an aggregate state for each function.
2. For each key update aggregate state for each.
3. For each unique key merge aggregate state for each function, in case multiple threads are used.
4. For each unique key insert result from aggregate state into final columns for each function.
1. A lot of virtual function calls.
2. For Nullable columns we have Nullable wrapper, additional indirection layer.
3. Aggregation combinators. -If, -Array, additional indirection layer.
Fuse multiple aggregate functions actions into one.
Functions require 4 actions: create, add, merge, insert. Fuse them and compile them into 4 functions.
1. Create function for multiple aggregate functions.
2. Add function for multiple aggregate functions.
3. Merge function for multiple aggregate functions.
4. Insert final result function for multiple aggregate functions.
1. Most common aggregate functions sum, count, min, max, avg, avgWeighted.
2. Combinators -If.
3. Nullable aggregate function adaptor.
SELECT
sum(UserID),
avg(ClientIP),
sum(CounterClass),
min(CounterID),
max(WatchID)
FROM default.hits_100m_obfuscated
GROUP BY WatchID
SELECT
sum_avg_sum_min_max(
UserID,
ClientIP,
CounterClass,
CounterID,
WatchID)
FROM default.hits_100m_obfuscated
GROUP BY WatchID
SELECT
sum(UserID),
sum(ClientIP),
sum(CounterClass),
sum(CounterID),
sum(WatchID)
FROM default.hits_100m_obfuscated
GROUP BY WatchID
— 0 rows in set. Elapsed: 5.504 sec. Processed 100.00 million rows, 2.50 GB (18.17 million rows/s., 454.21 MB/s.)
SET compile_aggregate_expression = 1;
SELECT
sum(UserID),
sum(ClientIP),
sum(CounterClass),
sum(CounterID),
sum(WatchID)
FROM default.hits_100m_obfuscated
GROUP BY WatchID
— 0 rows in set. Elapsed: 4.146 sec. Processed 100.00 million rows, 2.50 GB (24.12 million rows/s., 603.06 MB/s.)
— +34% performance improvement!
WITH (WatchID % 2 == 0) AS predicate
SELECT
minIf(UserID, predicate),
minIf(ClientIP, predicate),
minIf(CounterClass, predicate),
minIf(CounterID, predicate),
minIf(WatchID, predicate)
FROM default.hits_100m_obfuscated
GROUP BY WatchID
— 0 rows in set. Elapsed: 6.234 sec. Processed 100.00 million rows, 2.50 GB (16.04 million rows/s., 401.05 MB/s.)
SET compile_aggregate_expression = 1;
WITH (WatchID % 2 == 0) AS predicate
SELECT
minIf(UserID, predicate),
minIf(ClientIP, predicate),
minIf(CounterClass, predicate),
minIf(CounterID, predicate),
minIf(WatchID, predicate)
FROM default.hits_100m_obfuscated
GROUP BY WatchID
— 0 rows in set. Elapsed: 4.146 sec. Processed 100.00 million rows, 2.50 GB (24.12 million rows/s., 603.06 MB/s.)
— +71% performance improvement!

EXPLAIN PIPELINE SELECT WatchID FROM hits_100m_single
ORDER BY WatchID, CounterID;
┌─explain──────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Sorting) │
│ MergingSortedTransform 16 → 1 │
│ MergeSortingTransform × 16 │
│ LimitsCheckingTransform × 16 │
│ PartialSortingTransform × 16 │
│ (Expression) │
│ ExpressionTransform × 16 │
│ (SettingQuotaAndLimits) │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 16 0 → 1 │
└──────────────────────────────────────────┘
PartialSortingTransform — sort block, apply special optimization for LIMIT if specified.
MergeSortingTransform — sort blocks using k-way-merge algorithm, output stream of sorted blocks.
MergingSortedTransform — sort streams of sorted blocks using k-way-merge algorithm.
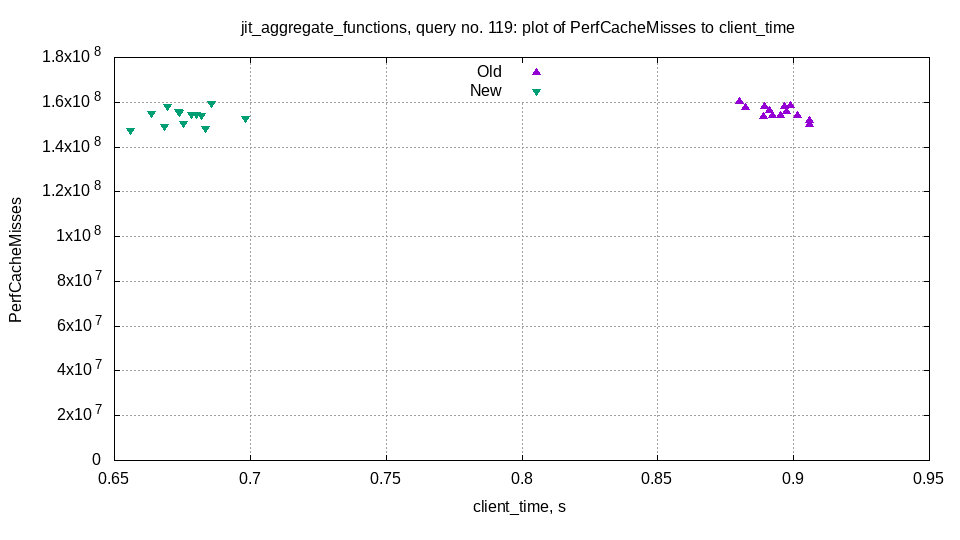
ORDER BY WatchID, CounterID
We will apply comparator to each row almost N * log(N) * 2 times during our MergeSortingTransform, MergingSortedTransform.
We can compile it in a single function, to avoid unnecessary indirections.
For Nullable columns performance could be even better.
SET compile_sort_description=0;
SELECT WatchID FROM hits_100m_single
ORDER BY WatchID, CounterID
— 0 rows in set. Elapsed: 6.408 sec. Processed 100.00 million rows, 1.20 GB (15.60 million rows/s., 187.26 MB/s.)
SET compile_sort_description=1;
SELECT WatchID FROM hits_100m_single
ORDER BY WatchID, CounterID
— 0 rows in set. Elapsed: 5.300 sec. Processed 100.00 million rows, 1.20 GB (18.87 million rows/s., 226.40 MB/s.)
— +20% performance improvement!
SET compile_sort_description=1;
SELECT * FROM test_nullable_table
ORDER BY value
— 0 rows in set. Elapsed: 5.299 sec. Processed 100.00 million rows, 1.70 GB (18.87 million rows/s., 320.81 MB/s.)
SET compile_sort_description=1;
SELECT * FROM test_nullable_table
ORDER BY value
— 0 rows in set. Elapsed: 4.131 sec. Processed 100.00 million rows, 1.70 GB (24.21 million rows/s., 411.50 MB/s.)
— +30% performance improvement!
JIT compilation improves performance of expression evaluation and aggregation.
For expression evaluation JIT compilation improves performance in 1.5-3 times (for some cases more than 20 times).
For aggregation JIT compilation improves performance in 1.15-2 times.
For order by comparator JIT compilation improves performance in 1.15-1.5 times